上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。
Apache Kafka
本文将介绍Apache Kafka在大数据领域的应用及其重要性,并提供一些代码实例来帮助读者更好地理解和应用Apache Kafka。文章主要包括以下几个方面:Apache Kafka的基本概念、Kafka在大数据处理中的角色、Kafka的架构和工作原理、如何使用Kafka进行数据流处理以及一些常见的使用场景。通过本文的阅读,读者将能够深入了解Apache Kafka,并学会如何使用它在大数据领域进行高效的数据处理。
随着大数据技术的快速发展,企业面临着处理大规模数据的挑战。Apache Kafka作为一个高性能、可扩展、分布式的消息队列系统,已经成为大数据处理领域中不可或缺的一部分。Kafka的设计目标是提供一种可靠的、持久化的、高吞吐量的数据流平台,使得实时数据的收集、传输和处理变得更加简单高效。

一、Apache Kafka的基本概念
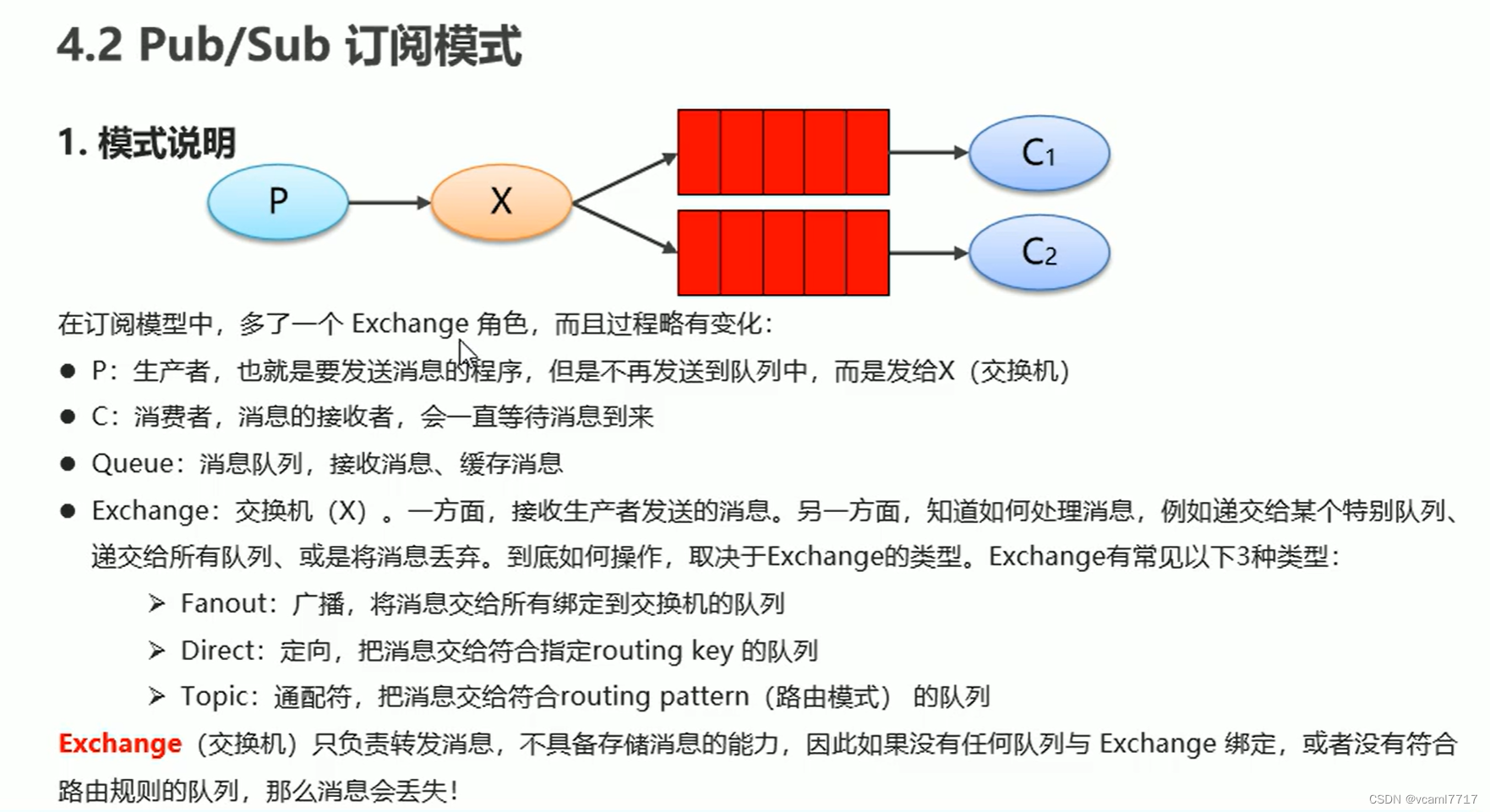
Kafka中的数据流被组织成一个个主题,每个主题包含一个或多个分区。
主题可以被划分为多个分区,每个分区都是一个有序的消息队列。
生产者将数据发布到Kafka的主题中。
消费者从Kafka的主题中读取数据。
多个消费者可以组成一个消费者组,共同消费一个主题的数据。
二、Kafka在大数据处理中的角色
数据采集: Kafka可以作为数据采集的中间件,接收来自各种数据源的实时数据。
数据缓冲: Kafka提供高吞吐量的消息传输,可以作为数据缓冲层,使得数据流能够平滑地传输到后续处理阶段。
数据集成: Kafka可以将多个数据源的数据进行集成,实现数据的汇总和聚合。
实时处理: Kafka可以与实时处理框架(如Apache Storm、Apache Flink)结合使用,实现实时数据的流式处理。
三、Kafka的架构和工作原理
生产者端架构: 生产者将数据发送到Kafka集群,其中包括了消息的分区和副本分配策略。
消费者端架构: 消费者通过订阅主题来消费数据,消费者组中的消费者
将主题的分区进行分配,并通过消费者位移来实现消息的顺序消费和容错机制。
中间件架构: Kafka由多个Broker组成的集群,每个Broker负责存储和处理分区的数据,具有高可用性和可扩展性。
工作原理: Kafka使用消息提交的方式来实现数据的持久化存储,并通过日志结构和批量传输等技术来提高吞吐量和性能。
四、使用Kafka进行数据流处理
生产者代码:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
String topic = "my_topic";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
String message = "Message " + i;
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Error sending message: " + exception.getMessage());
} else {
System.out.println("Message sent successfully! Topic: " + metadata.topic() +
", Partition: " + metadata.partition() + ", Offset: " + metadata.offset());
}
}
});
}
producer.close();
}
}
消费者代码:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
String topic = "my_topic";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("group.id", "my_consumer_group");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value() +
", Topic: " + record.topic() +
", Partition: " + record.partition() +
", Offset: " + record.offset());
}
consumer.commitSync();
}
}
}
常见的Kafka使用场景
实时日志处理: Kafka可以作为实时日志流的收集和传输平台,方便进行实时监控和分析。
流式ETL: Kafka可以将多个数据源的数据进行整合和转换,实现流式ETL(Extract-Transform-Load)过程。
系统解耦和异步通信: Kafka作为消息队列,可以实现不同系统之间的解耦和异步通信,提高系统的可伸缩性和可靠性。
实时流处理: Kafka可以与实时流处理框架(如Apache Spark、Apache Flink)结合使用,进行实时数据流处理和分析。
数据备份和灾难恢复: Kafka的持久化存储和副本机制可以用于数据备份和灾难恢复,确保数据的可靠性和持久性。
结论
Apache Kafka作为大数据领域中重要的消息队列系统,在数据采集、数据缓冲、数据集成和实时处理等方面发挥着关键作用。本文介绍了Kafka的基本概念、在大数据处理中的角色、架构和工作原理,以及使用Kafka进行数据流处理的示例代码。此外,还探讨了Kafka的常见使用场景。通过学习和应用Apache Kafka,企业可以更好地处理大规模数据,并实现高效的数据流处理。