嵌入式硬件
刘一哥
apache
集群模式
MIT
flink watermark
rnn
斐波那契
sklearn
博通蓝牙vendor
遥感预处理
流程图
kali
文件挂载
寄生-捕食算法
tensorflow
数据驱动
微信公众平台
include
贝叶斯
相关文章

算法与数据结构之递归
要点
搞清楚递归函数的作用处理当前状态和下一递归状态的关系处理好递归的出口
举例
反转链表 当前递归函数的作用:反转链表,并返回新的头结点。当前状态和下一递归状态的关系:递归调用ReverseList(head.next),函数会返回新的头…
算法与数据结构之二分查找
要点
找出判断的条件何时退出循环
举例 无重复数字的普通二分查找 找出判断的条件:用arr[mid]和target去比较。如果arr[mid] target时,返回mid;如果arr[mid] > target时,说明要找的值在左边,right mid - 1&…
基于MapReduce的WordCount
MapReduce是一种编程模型,将任务分为两个阶段:Map和Reduce,用户只需编写map()和reduce()两个函数就可以完成简单的分布式程序的设计。 MapReduce能够解决的问题有一个共同特点:任务可以被分解成多个子问题,且这些子问题…
MySQL给表添加create_time和update_time字段并且设置触发器
如何实现
SQL
ALTER TABLE <表名>
ADD COLUMN create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP AFTER <create_time前一个字段>,
ADD COLUMN update_time timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP AFTER create_time;S…
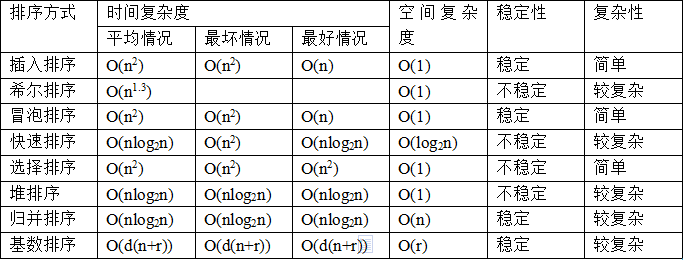

数据仓库系列文章整理
声明:此系列文章来自http://webdataanalysis.net/category/web-data-warehouse/ 数据仓库的价值 相信大家都了解数据仓库的4个基本特征:面向主题的、集成的、相对稳定的、记录历史的,而数据仓库的价值正是基于这4个特征体现的:
1…